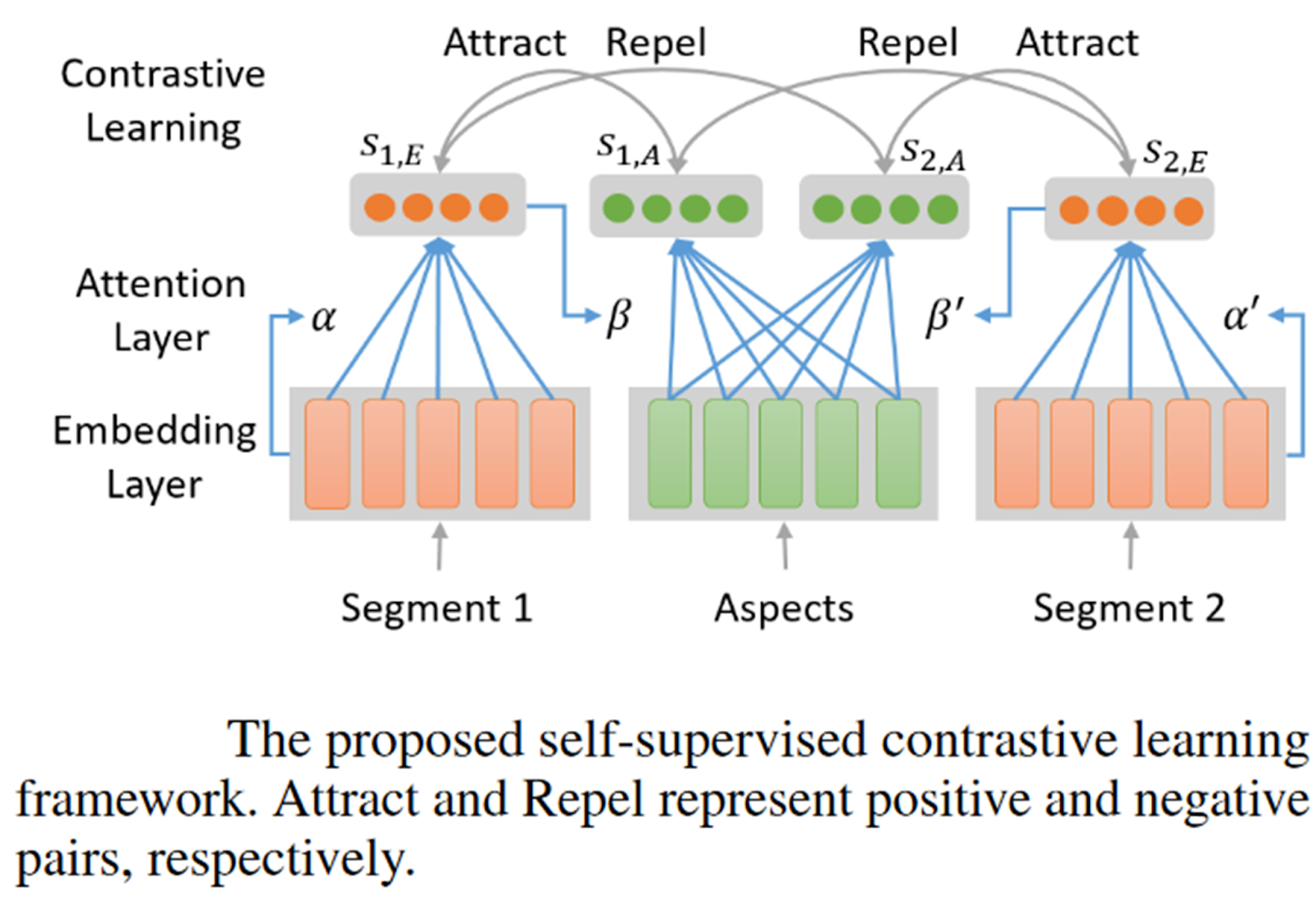
Contrastive learning is revolutionizing neural network training by introducing a new paradigm. This innovative approach eliminates the need for extensive labeling and allows deep learning models to learn high-level features through the comparison and contrast of data samples. By leveraging unlabeled data, contrastive learning is transforming the field of representation learning and self/semi-supervised learning paradigms.
In domains like music information retrieval and computer vision, contrastive learning is making significant strides. Its ability to teach models to differentiate and recognize patterns without the need for large amounts of labeled data is revolutionizing how neural networks are trained. The impact of this new approach is reshaping the landscape of neural network training.
Contrastive Learning is a machine learning paradigm that has revolutionized the field by providing a powerful training approach for deep learning models. In this paradigm, the focus is on utilizing **unlabeled data** to teach the model to **recognize similarities and differences** between data points. By comparing and contrasting samples belonging to **similar and different distributions**, the model learns to differentiate and identify patterns.
Unlike traditional supervised learning methods that heavily rely on labeled data, contrastive learning reduces the need for extensive labeling. This makes it particularly valuable in situations where labeled data is limited or expensive to obtain. By leveraging **unlabeled data**, contrastive learning enables deep learning models to generalize better and improve their performance on various tasks.
In contrastive learning, the key idea is to compare data points and create representations that bring similar data points closer and push different data points apart. This allows the model to learn meaningful representations without explicit annotations or manual labels.
The crux of contrastive learning lies in the concept of **similar data points** and **different distributions**. When comparing similar data points, the model aims to bring them closer in the feature space, indicating their shared characteristics. Conversely, when comparing data points from different distributions, the model seeks to increase their separation, highlighting their disparities.
By training deep learning models through contrastive learning, researchers have achieved remarkable results in various domains, including computer vision and natural language processing. The core principle of **contrastive learning** is to enable the model to capture the underlying structure and relationships within the data without the need for extensive labeled datasets.
Table: Comparison of Contrastive Learning with Other Machine Learning Paradigms
Machine Learning Paradigm
Focus
Main Dataset Requirement
Performance on Unlabeled Data
Supervised Learning
Prediction
Highly Labeled
Weak
Unsupervised Learning
Data Representation
No Labels
Moderate
Contrastive Learning
Data Comparison
Unlabeled Data
Strong
Contrastive learning outperforms traditional supervised and unsupervised learning approaches in terms of utilizing **unlabeled data** effectively and enhancing performance. By comparing and contrasting data points, contrastive learning allows neural networks to learn rich representations without the need for explicit annotations or extensive labeling efforts.
How does Contrastive Learning Work?
In Contrastive Learning, a deep learning model focuses on maximizing the distance between samples from different distributions (negative samples) and minimizing the distance between samples from the same distribution (positive samples) in the latent space. By doing so, the model learns to recognize similarities and differences between the data.
The process begins by training the deep learning model using various techniques, such as instance discrimination and image subsampling/patching. Instance discrimination involves comparing and contrasting different data samples to teach the model which points are similar and which are different. This technique helps the model learn high-level features effectively.
Contrastive learning provides a powerful approach for training deep learning models without the need for extensive labeled data. By leveraging the properties of the latent space, the model can effectively separate samples belonging to different distributions while pulling together samples from the same distribution.
The latent space represents the learned features of the data. Through contrastive learning, the deep learning model works to maximize the inter-class distance, ensuring that negative samples are far apart in the latent space. Simultaneously, it minimizes the intra-class distance to bring positive samples closer together, emphasizing their similarities.
The choice of positive and negative samples plays a crucial role in the model’s ability to learn and recognize patterns. Careful selection of these samples ensures that the model can distinguish between different classes and generalize well to unseen data.
Overall, contrastive learning provides a powerful framework for training deep learning models, allowing them to effectively learn high-level features by maximizing distance between different distributions and minimizing distance within the same distribution.
Benefits of Contrastive Learning:
Enhanced performance of deep learning models
Reduction in the need for large amounts of labeled data
Improved generalization capabilities
Effective representation learning
Applications in various domains, including computer vision and natural language processing
Challenges of Contrastive Learning:
Selection of appropriate positive and negative samples
Complexity in choosing the right architecture and hyperparameters
Performance degradation with limited or insufficient data
Contrastive Learning Techniques
Advantages
Instance Discrimination
Does not require explicit labeling
Triplet Loss
Encourages discrimination between positive and negative samples
N-pair Loss
Considers multiple negative samples alongside a positive sample
Contrastive Learning Frameworks
Contrastive learning, with its ability to enhance the performance of deep learning models, has given rise to various frameworks that are specifically designed to leverage the power of contrastive learning. These frameworks offer unique approaches and loss functions to optimize the learning process and improve model accuracy.
Instance Discrimination
One popular framework is instance discrimination, which utilizes the entire image or audio sample as positive samples. By training the model to distinguish between different instances of the same class, it encourages the model to learn robust representations. This framework is particularly effective in domains where each sample is unique, such as facial recognition and speaker verification.
Triplet Loss
Another widely used framework is triplet loss. In triplet loss, the model learns to compare an anchor sample with a positive sample (from the same class) and a negative sample (from a different class). The goal is to minimize the distance between the anchor and the positive sample while maximizing the distance between the anchor and the negative sample. This framework allows the model to learn discriminative features by embedding similarities and differences within the latent space.
N-pair Loss
The N-pair loss framework extends the concept of triplet loss by incorporating multiple negative samples for each anchor sample. This approach further enriches the learning process by exposing the model to a broader range of negative samples. By sampling multiple negatives alongside an anchor sample, the model gains a more comprehensive understanding of the differences between classes, leading to improved performance in various classification tasks.
“The development of contrastive learning frameworks like instance discrimination, triplet loss, and N-pair loss has significantly contributed to the advancement of deep learning models. These frameworks provide efficient solutions for selecting positive and negative samples and guiding the training process towards more accurate and meaningful representations.”
The following table summarizes the contrastive learning frameworks and their characteristics:
– Compares anchor, positive, and negative samples – Embeds similarities and differences
N-pair Loss
– Uses multiple negatives per anchor sample – Provides broader range of negatives
These contrastive learning frameworks offer powerful tools for training deep learning models and improving their performance in various domains. The choice of framework depends on the specific requirements of the task at hand, as well as the characteristics of the dataset.
Applications of Contrastive Learning
Contrastive learning, with its ability to learn high-level features from unlabeled data, has found numerous applications in domains such as computer vision and music information retrieval.
Computer Vision
In the field of computer vision, contrastive learning has shown promising results in various tasks:
Image Classification: By leveraging contrastive learning, deep learning models can effectively classify images into different categories, even when labeled data is limited. The models learn to distinguish between different images based on their visual features, thus improving classification accuracy.
Object Detection: Contrastive learning enhances object detection capabilities by enabling the models to recognize and locate objects in images accurately. This application is crucial in numerous domains, including autonomous driving and surveillance systems.
Image Generation: Contrastive learning can also be utilized for image generation tasks, allowing the models to create realistic images based on learned features and distributions. This application has significant implications in fields like graphic design and content creation.
Music Information Retrieval
Contrastive learning has made significant contributions to the field of music information retrieval:
Musical Representations: By applying contrastive learning techniques, models can learn meaningful representations of music, capturing the intricate patterns and structures present in different audio samples. This helps in tasks such as music transcription, genre classification, and similarity analysis.
Music Classification: Contrastive learning aids in improving the accuracy of music classification systems by enabling models to distinguish between different genres, styles, or moods. This can enhance recommendation algorithms and personalized music streaming platforms.
Recommendation Systems: Contrastive learning can also be utilized to enhance recommendation systems by understanding the similarities and differences between music tracks, enabling more accurate personalized recommendations for users.
The versatility of contrastive learning makes it applicable to a wide range of other data-driven tasks beyond computer vision and music information retrieval. Its ability to learn informative representations from unlabeled data has sparked interest in various fields, including natural language processing and speech recognition.
Illustration of the applications of contrastive learning in computer vision and music information retrieval.
Generalized Supervised Contrastive Learning
Generalized Supervised Contrastive Learning is an extension of supervised contrastive learning that elevates the capabilities of deep neural networks by fully utilizing label distributions. By incorporating the Generalized Supervised Contrastive Loss, the model can measure the cross-entropy between label similarity and latent similarity, enabling a more comprehensive understanding of the data. This enhanced approach allows deep neural networks to benefit from existing techniques like CutMix and knowledge distillation, which exploit label information as a probability distribution.
Generalized Supervised Contrastive Learning has proven to be highly effective, achieving state-of-the-art accuracies on popular datasets such as ImageNet, CIFAR10, and CIFAR100. This approach revolutionizes the training process of deep neural networks by optimizing the utilization of label distribution information, leading to improved performance and accuracy.
Benefits of Generalized Supervised Contrastive Learning
1. Enhanced Label Information: Generalized Supervised Contrastive Learning maximizes the utilization of label distributions, allowing deep neural networks to gain a deeper understanding of the data.
2. Improved Accuracy: By incorporating the generalized loss, deep neural networks achieve state-of-the-art accuracies on popular datasets.
3. Compatibility with Existing Techniques: Generalized Supervised Contrastive Learning seamlessly integrates with other techniques like CutMix and knowledge distillation, providing a comprehensive training framework.
“Generalized Supervised Contrastive Learning bridges the gap between label distributions and latent similarity, enabling a more robust and accurate training process for deep neural networks.” – Research Scientist, Toronto AI Institute
Comparison of Generalized Supervised Contrastive Learning with Traditional Approaches
Approach
Advantages
Disadvantages
Supervised Contrastive Learning
– Effective utilization of labeled data – Improved generalization
– Limited to binary classification – Difficulty handling label noise
Generalized Supervised Contrastive Learning
– Enhanced utilization of label distributions – State-of-the-art accuracies – Compatibility with existing techniques
– More complex loss function – Increased computational cost
Generalized Supervised Contrastive Learning represents a significant advancement in the field of deep neural network training. By leveraging label distributions and incorporating the Generalized Supervised Contrastive Loss, deep neural networks can achieve unprecedented accuracy on various datasets. This approach holds immense potential for advancing the capabilities of deep neural networks in a wide range of domains.
Conclusion
Contrastive learning is revolutionizing the field of neural network training by providing a new paradigm for representation learning. By eliminating the need for extensive labeling, this approach allows deep learning models to learn high-level features more efficiently. Through the comparison and contrast of data samples, these models can recognize underlying patterns and make accurate predictions across various domains.
The development of frameworks such as instance discrimination, triplet loss, and N-pair loss has further enhanced the effectiveness of contrastive learning. These frameworks enable the models to maximize the differences between samples from different distributions and minimize the differences between samples from the same distribution in the latent space. This optimization process contributes to the models’ ability to extract meaningful representations and achieve higher performance.
With its diverse applications in computer vision, music information retrieval, and other data-driven tasks, contrastive learning is shaping the future of neural network training. Its versatility and effectiveness in learning latent representations make it a powerful technique for improving the performance of deep learning models. As research in this field continues to evolve, contrastive learning will undoubtedly play a pivotal role in advancing representation learning and enhancing the capabilities of neural networks.
FAQ
What is contrastive learning?
Contrastive learning is a machine learning paradigm where unlabeled data points are compared against each other to teach a model which points are similar and which are different. By contrasting samples belonging to the same distribution and samples belonging to different distributions, the model learns to differentiate and recognize patterns. This approach reduces the need for large amounts of labeled data and enhances the performance of deep learning models.
How does contrastive learning work?
In contrastive learning, a deep learning model aims to maximize the distance between samples belonging to different distributions (negative samples) and minimize the distance between samples belonging to the same distribution (positive samples) in the latent space. The model is trained using different techniques such as instance discrimination and image subsampling/patching. The choice of positive and negative samples plays a crucial role in the model’s ability to learn and recognize similarities and differences.
What are some contrastive learning frameworks?
Several contrastive learning frameworks have been proposed to enhance the performance of deep learning models. These include instance discrimination, where the whole of an image or audio sample is used as positive samples, triplet loss, where an anchor sample is compared with a positive and a negative sample, and N-pair loss, where multiple negative samples are sampled alongside an anchor sample. Each framework has its own loss function and techniques for selecting positive and negative samples.
What are the applications of contrastive learning?
Contrastive learning is being applied in various domains, including computer vision and music information retrieval. In computer vision, contrastive learning has shown promising results in tasks such as image classification, object detection, and image generation. In music information retrieval, contrastive learning is used to learn musical representations and improve music classification and recommendation systems. The versatility of contrastive learning makes it applicable to a wide range of data-driven tasks.
What is generalized supervised contrastive learning?
Generalized supervised contrastive learning is an extension of supervised contrastive learning that allows the model to fully utilize label distributions. It enhances the capabilities of supervised contrastive loss by measuring the cross-entropy between label similarity and latent similarity. By incorporating this generalized loss, deep neural networks can benefit from various existing techniques, such as CutMix and knowledge distillation, that exploit label information as a probability distribution. Generalized supervised contrastive learning has achieved state-of-the-art accuracies on popular datasets such as ImageNet, CIFAR10, and CIFAR100.
How is contrastive learning revolutionizing neural network training?
Contrastive learning is revolutionizing the field of neural network training by providing a new paradigm for representation learning. It allows deep learning models to learn high-level features without the need for extensive labeling. By comparing and contrasting data samples, the models can recognize patterns and make accurate predictions in various domains. The development of frameworks like instance discrimination, triplet loss, and N-pair loss has further enhanced the effectiveness of contrastive learning. With its applications in computer vision, music information retrieval, and other data-driven tasks, contrastive learning is shaping the future of neural network training.
Few-shot learning is revolutionizing the field of artificial intelligence (AI) by enabling models to adapt and learn new tasks with minimal data. This breakthrough approach allows models to excel in…
Neural Turing Machines (NTMs) are revolutionizing the field of artificial intelligence by integrating AI with human-like memory processing capabilities. This integration is transforming the way we perceive AI, emphasizing the…
Restricted Boltzmann Machines (RBMs) are the fundamental components of Deep Belief Networks (DBNs), which have revolutionized the field of artificial intelligence (AI). RBMs are two-layered generative stochastic models that have…
In the world of spatial-temporal data analysis, Convolutional LSTM Networks offer a cutting-edge integration that brings precision and accuracy to predicting events such as ice-jams and travel times. These advanced…
Self-Organizing Maps (SOMs) are a powerful tool for visualizing complex, high-dimensional data sets. In an era of rapidly growing data, the need for effective data visualization techniques is paramount. SOMs…
Neural style transfer (NST) is a fascinating technique that combines the fields of art and science, bringing together advanced AI algorithms with creative aesthetics. It offers a unique way to…